Why Microservice Architecture?
Nowadays with the rise of social media, fast internet, etc. The tendency to use applications is getting more and more. As a result of these behavior changes, monolithic applications need to deal with a tremendous majority of changes.
most businesses face a new feature that should be added to their application, on the other side, the amount of data that should be processed is getting much higher and in so many cases monolithic applications because of their drawbacks such as slow development velocity, slower deployment, as barely support the agile methodology which is the main idea to deal with fast changes in the software industry.
If we want to create a software project for a big or complex business (It’s not true about startup projects or those projects in the funding stage, because they have to be submissive to the time-to-market limitations) it’s better to start with microservice architecture.
So, one of the solutions to boost the application flexibility, scalability, and so many other concerns is to follow a flexible architecture like microservice-based architecture.
Why do we need a roadmap?
As I understand so many developers, want to know how they should start this journey, obviously, there are thousands of resources that can be used, but the problem is the dispersion of resources. I decided to make this journey more clear by defining a road map for this learning curve.
How does this roadmap work?
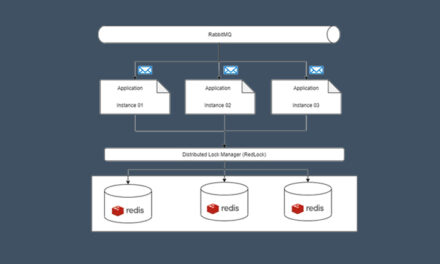
A microservice-based architecture has several discrete units that work together to receive and process requests from various sources. Some parts of this complex can be plug-in units, which means in case of need either we can plug a new unit or unplug a unit, which shouldn’t disturb the overall work of an application.
For example, if we have decided to implement a microservice architecture, we should be familiar with various concerns in the life cycle of an application such as persistence, logging, monitoring, load balancing, caching, etc. Besides we should know which tools or which stack are more suitable for our applications.
Well, this is the main approach of my article, I will explain the concern, then introduce some of the best tools for satisfying the needs.
I explain each topic to answer these questions:
1. What is it?
2. Why should I use it?
3. Which tools are better?
Notice that I have mentioned for tools part just two or three tools, Of course, we have so many other tools, the criterion for choosing these tools is popularity, performance, being open-source, and also update frequency.
Notice again we have also cloud-based services which are out of the scope of this article to be discussed.
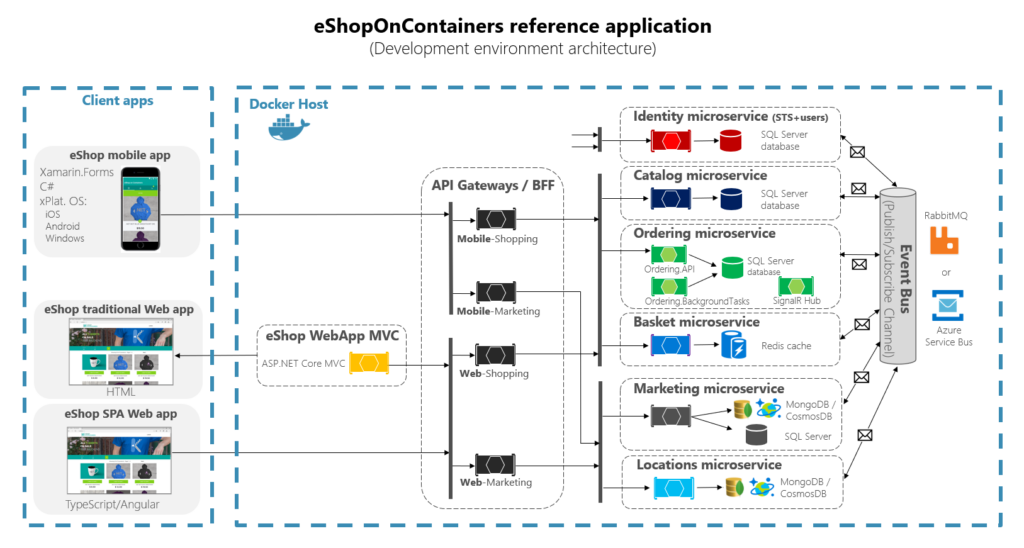
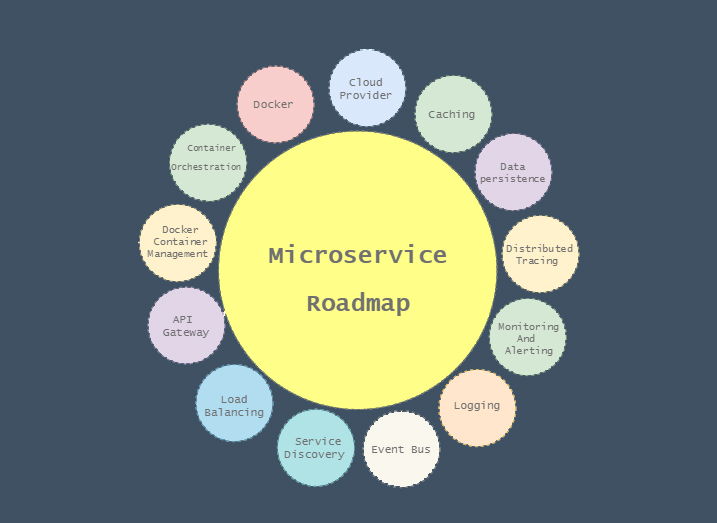
I have used the above diagram as the architecture diagram sample, because this diagram involves most of the microservice architecture components and also has been recognized as a standard model, of course, I know this diagram is not a very comprehensive diagram, but I have tried to keep this article as simple as possible, maybe in future I would revise the article and write a new version of that. I think the best mindset about explaining every concept, should always follow the KISS pattern.
Docker
What
Docker is an open-source platform for containerizing our applications, with the libraries, and dependencies that our application needs to run in various environments. with the help of Docker, development teams are able to package applications into containers.
Why
Actually, Docker is one of the tools to containerize applications, Which means we are also able to create containers without using Docker, The real benefit of Docker is to make this process easier, safer, and much simpler.
Tools
Docker Inc
Container Orchestration
What
After we containerize our application, we will need some tools for managing containerized applications for doing some manual and automated operations like horizontal scaling.
Why
These tools provide some services for our application management like automated load-balancing, and guarantee high service availability. This kind of service is done by defining several manager nodes, and in case of any failure in one node manager, the other managers can keep the application services available.
Tools
Kubernetes or K8s ,Docker Swarm
Docker Container Management
What
Managing Docker environment, configuration management, and providing the environment security, etc. These concerns can be centralized and automated by a docker container management tool.
Why
A Docker container management tool provides a GUI-based tool for users, and they do not have to deal with CLI which is not comfortable for all users. These tools give developers a rich UI to build and publish their images, and also make it much easier to do some operational tasks such as services horizontally scaling by providing a simplified user interface.
Tools
Portainer, DockStation, Kitematic, Rancher
API Gateway
What
An API gateway can be considered as an API management tool that works as a middleware between our application services and different clients. An API gateway can manage many things such as:
Routing: a gateway receives all API requests and forwards them to the destination services.
Logging: we will be able to log all the requests in one place.
Authorization: check if we as a user are eligible to access the service or not, if not the request can be short-circuited
Performance profiling: we can estimate every request execution time and check our application bottlenecks.
Caching: By handling our caching at the gateway level, we would eliminate so much traffic on our services.
In fact, It works as a reverse proxy, and clients just need to know about our gateway and application services can be hidden from the outside.
Why
Without an API gateway, we may need to do some cross-cutting concerns in every service, for example, if we want to log the request and response for services. Besides, if our application consists of several services, our client needs to know about each service address, and in case of changing a service address, several places should be updated.
Tools
Kong, Ocelot
Load Balancing
What
One of the most important reasons that we have chosen the microservice architecture is scalability, Which means we will be able to handle more requests by running more instances of our services, but the question is, which instance should receive requests or How do clients know which instance of service should handle the requests?
The answer to these questions is Load Balancing. Load Balancing means sharing the income traffic between a service instance.
Why
In order to scale our independent services, we need to run several instances of the services. With a load balancer, clients do not need to know the right instances which serving.
Tools
Traefik, NGINX, Seesaw
Service Discovery
What
As our application services count more and more, services need to know each other service instance addresses, but in large applications with lots of services, this cannot be handled. So we need service discovery which is responsible for providing all component addresses in our application, they could easily send a request to the service discovery service and get the available services instance address.
Why
When we can have several services in our application, service discovery is a must-have for our application. our application services don’t need to know each service instance address, it means service discovery paves this way for us.
Tools
Consul, Zookeeper, Eureka, etcd, and Keepalived
Event Bus
What
In the microservice architecture pattern, we would use two different types of communication, Sync and Async communication.
Sync communication means services call each other through an HTTP call or GRPC call. Async communication means services interact with each other via a message bus or an event bus, It means there is no direct connection between services.
Our architecture can use both communication styles simultaneously, for instance in an online shop example we can send a message whenever an order is registered and those services that have subscribed to a specific channel will receive the message. But sometimes we may need some real-time inquiry, for instance, if we need to know the quantity of an item, may use GRPC or HTTP call between services to get the response.
Why
If we want to have a scalable application with several services, one of the principles we would follow is to create loosely coupled services that interact with each other through an event bus. Also, if we need to create an application that is able to plug in a new service to receive a series of specific messages, we need to use an event bus.
Tools
RabbitMQ, Kafka
Logging
What
When using a microservice architecture pattern it’s better to centralize our services logs. These logs would be used in debugging a problem or aggregating logs according to their types for analytical usage.
Why
In case of any need to debug a request, we may face difficulty if we do not gather service logs in one place. we are also able to correlate the logs related to a specific request with a unique correlation ID. It means all logs in different services related to a request will be accessible by this correlation ID.
Tools
Elastic Logstash
Monitoring And Alerting
What
In a microservice architecture, if we want to have a reliable application or service we have to monitor the functionality, performance, communication, and any other aspects of our application in order to achieve a responsible application.
Why
We need to monitor the overall functionality and service health and also need to monitor performance bottlenecks and prepare a plan to fix them. Optimize user experience by decreasing the downtime of our service by defining early alerts for our services at critical points. Monitor overall resource consumption of services, when they are under heavy load and etc.
Tools
Prometheus, Kibana, Grafana
Distributed Tracing
What
Debugging is always one of the developers’ concerns, As we, all have the experience to trace or debug a monolithic. It’s very straightforward and easy, But when it comes to microservice architecture, a request may be passed through different services, which makes it difficult to debug and trace because the codebase is not in one place, so here distributed tracing tool can be helpful.
Why
Without a distributed tracing tool it’s frustrating or maybe impossible to trace our request through different services. With these tools, we can easily trace requests and events with the help of a rich UI for demonstrating the flow of the request.
Tools
OpenTelemetry, Jeager, Zipkin
Data Persistence
What
In most systems, we need to persist data, because we would need the data for further processes or reporting, etc in order to persist data, we need some tool to write our application data into physical files with different structures.
Why
In monolithic applications, we used to have one or two different persistence types and most monolithic applications use Relational databases like SQL Server, Oracle, and MySQL. But in microservice architecture, we should follow the DataBase per service pattern, which means keeping each microservice’s persistent data private to that service and accessible only via its API.
Well, We would have different databases for different usages and scenarios. For instance, a report service might use NoSQL databases like ElasticSearch or MongoDB, because they use document base structure, It means the structure for persisting data in these databases is different from relational databases, which are suitable for services with high rates of reading or fetching data.
On the other hand, we may need relational databases like Oracle or SQL SERVER in some microservices or we may also need some databases which support graph structure or key-value structure.
So, In Microservice architecture according to the service mission we would need different types of databases.
Tools
Relational databases: PostgreSQL, MySQL, SQL SERVER, Oracle
Non-Relational databases: MongoDB, Cassandra, Elasticsearch
Caching
What
Caching reduces latency in service-to-service communication of microservice architectures. A cache is a high-speed data storage layer that stores a subset of data. When data is requested from a cache, it is delivered faster than if we accessed the data’s primary storage location.
Why
In a microservice architecture, there are many strategies in which caching can be implemented in those ways. Such as
1- Embedded Cache (distributed and non-distributed)
2- Client-Server Cache (distributed)
3- Reverse Proxy Cache (Sidecar)
In order to reduce latency, caching can be implemented in different layers. It means we would have a higher response time. besides we can also implement distributed caching which is accessible for several microservices and sometimes considered as a placeholder for shared resources, which have different usage, like Rate-limiting. The most common reason for rate-limiting is to improve the availability of API-based services by avoiding resource starvation.
Tools
Redis (Remote Dictionary server), Apache Ignite, Hazelcast IMDG
Cloud Provider
What
A cloud service provider is a third-party company offering a cloud-based platform, infrastructure, application, or storage services. Much like a homeowner would pay for a utility such as electricity or gas, companies typically have to pay only for the amount of cloud services they use, as business demands require.[Microsoft]
The most important categories for cloud providers
1- Software as a Service (SaaS).
2-Platform as a Service (PaaS).
3- Infrastructure as a Service (IaaS).
Why
One benefit of using cloud computing services is that firms can avoid the upfront cost and complexity of owning and maintaining their own IT infrastructure, and instead simply pay for what they use, when they use it. Today, rather than owning their own computing infrastructure or data centers, companies can rent access to anything from applications to storage.
Tools
Amazon Web Services (AWS), Microsoft Azure, Google Cloud, Alibaba Cloud
Continual Update
Learn More …
- Building Evolutionary Architectures (short review of the book)
Conclusion
In this article, I tried to demonstrate a roadmap associated with microservice architecture patterns. If we want to implement a microservice architecture from scratch or migrate our monolithic to microservice architecture, we will need to know these concepts.
Besides these concepts, we have other concepts like service mesh, caching, and persistence that could be a part of this roadmap, but I intentionally have not mentioned them, for the sake of simplicity and with a view to brevity.
Cheers, Matt Ghafouri